Blood-brain barrier permeability peptide prediction
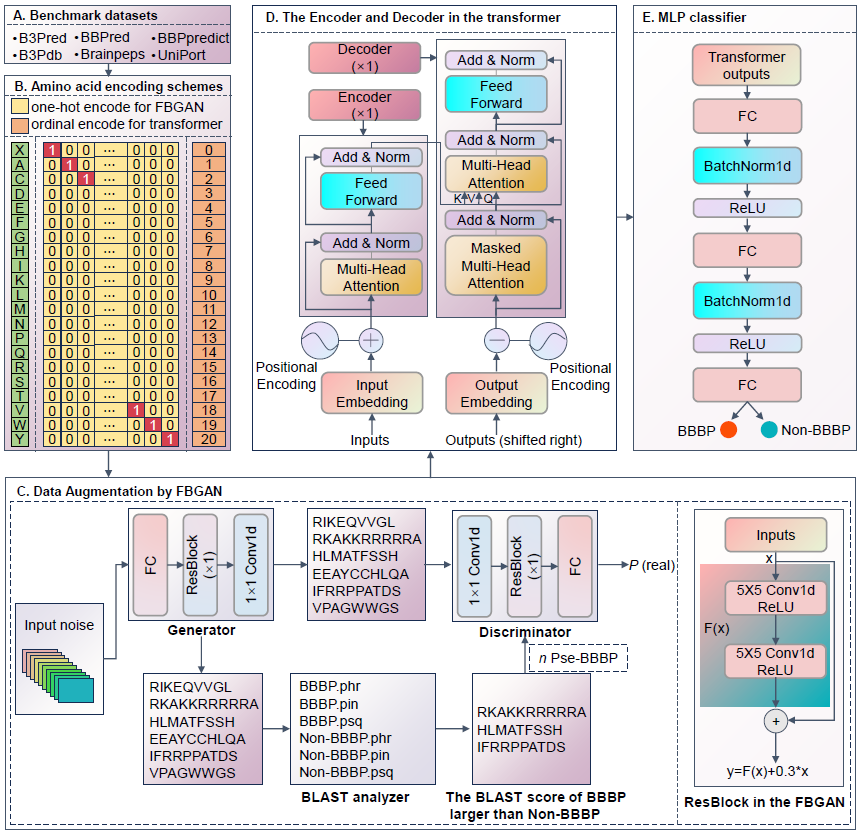
The workflow of the DeepB3P comprising five steps: data acquisition and processing (A); amino acid embedding (B); data augmentation using FBGAN (C); and the neural network architecture of DeepB3P (D, E).
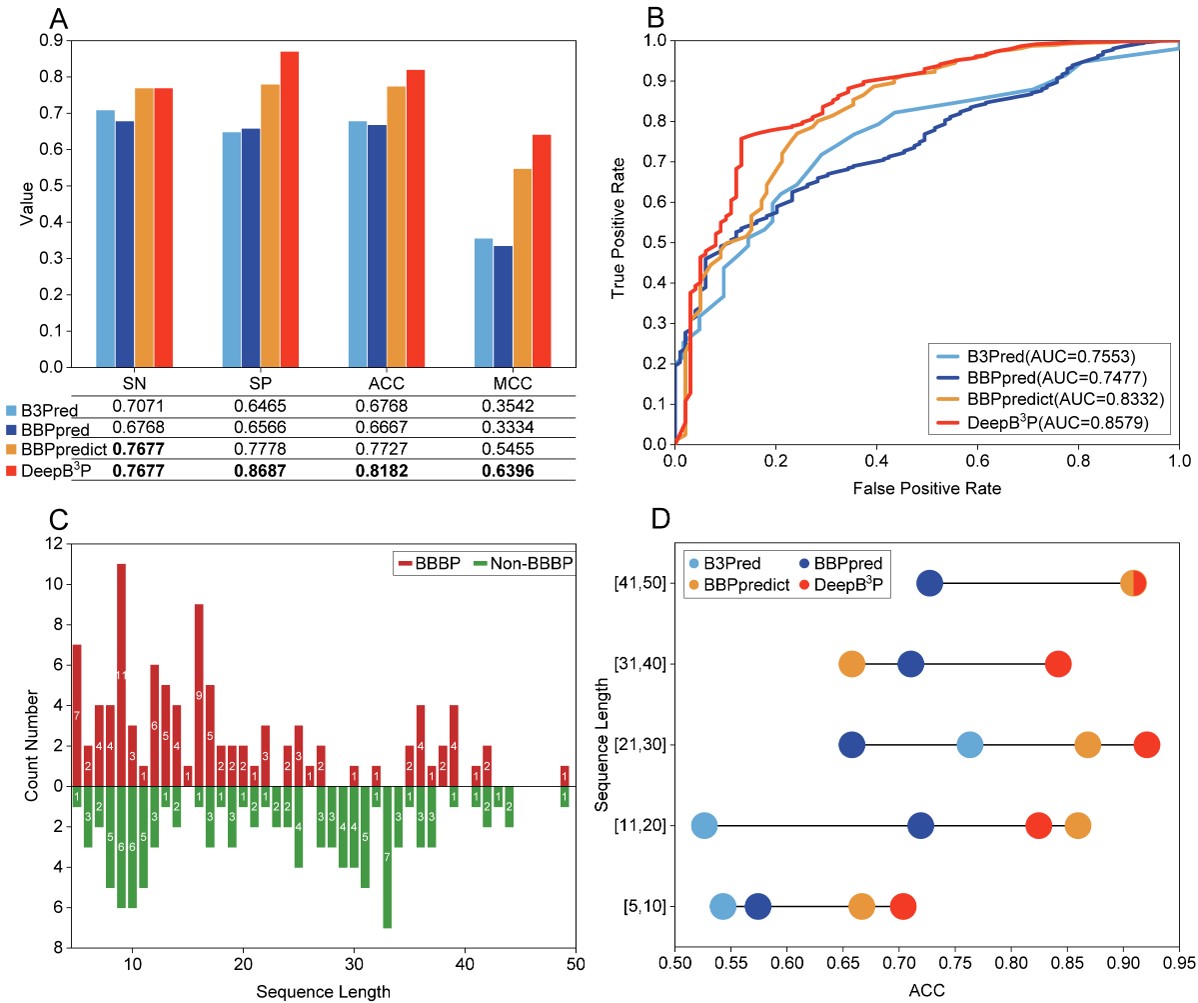
We compared DeepB3P with three baseline methods, namely, B3Pred, BBPpred, and BBPpredict.
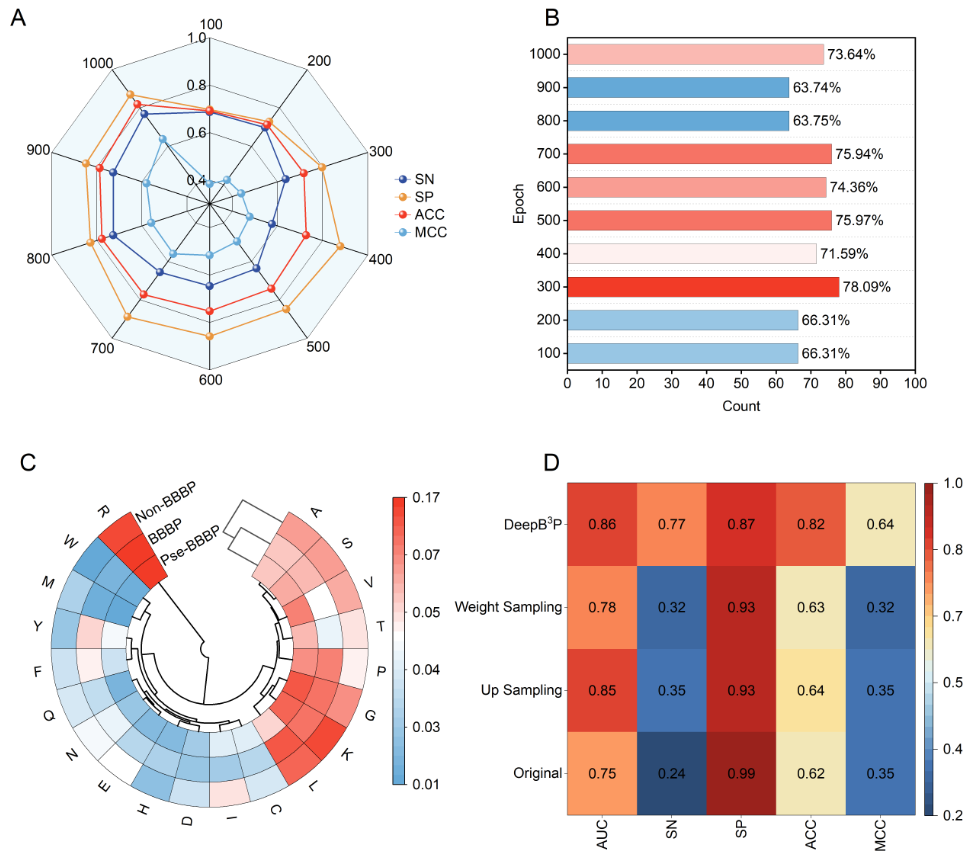
The number of the FBGAN training process consisted of 1,000 epochs. For every 100 epoches, both the 6,522 sequences (Pse-BBBPs) generated by the generator and BBBPs were utilized as positive dataset to train our proposed model, and the model is evaluated using the testing dataset.
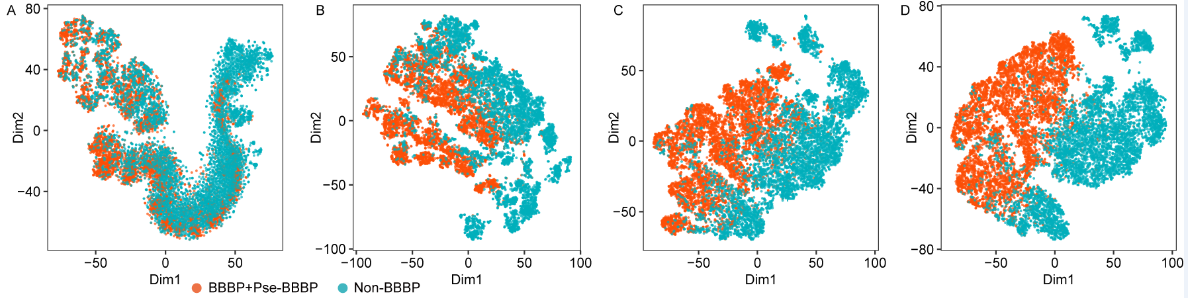
The t-SNE visualization of the features. (A) the t-SNE visualization of the initial features. (B)-(D) are the t-SNE visualization of the features acquired from the transformer decoder, encoder and the penultimate layer of DeepB3P, respectively. it is evident that the initial features were randomly distributed (A), whereas a more pronounced clustering effect becomes apparent after the encoder layer (B). The decoder layer additionally retained the crucial classification features, resulting in distinct clusters for BBBPs and Non-BBBPs (C). Ultimately, accurate identification was accomplished through the classification layer and softmax function (D).