帮助与文档
快速入门指南
1. 数据库概述
我们的数据库包含三个主要部分:
- 次生代谢物: 由生物体产生的化合物
- 小肽: 氨基酸短链
- 小RNA: 小RNA分子
2. 搜索功能
每个部分都提供:
- 高级搜索功能
- 可排序列
- 分页(每页15项)
3. 数据显示
所有数据表都包括:
- 可排序列(点击列标题)
- 用于过滤结果的搜索框
- 页面导航控件
- 适用于所有设备的响应式设计
常见问题
如何搜索特定数据?
使用任何数据表顶部的搜索框。您可以输入相关字符进行搜索。
如何对数据进行排序?
点击任何列标题以按该列排序。再次点击以反转排序顺序。
如何在页面之间导航?
使用每个表格底部的分页控件在结果页面之间移动。
不同的证据类型是什么意思?
有三种证据类型:
- E: 代表实验数据(Experimental)
- D: 代表来源于GNDC数据库
- G: 代表基因组解析
如何使用分析工具?
工具页面提供三个分析模块:
-
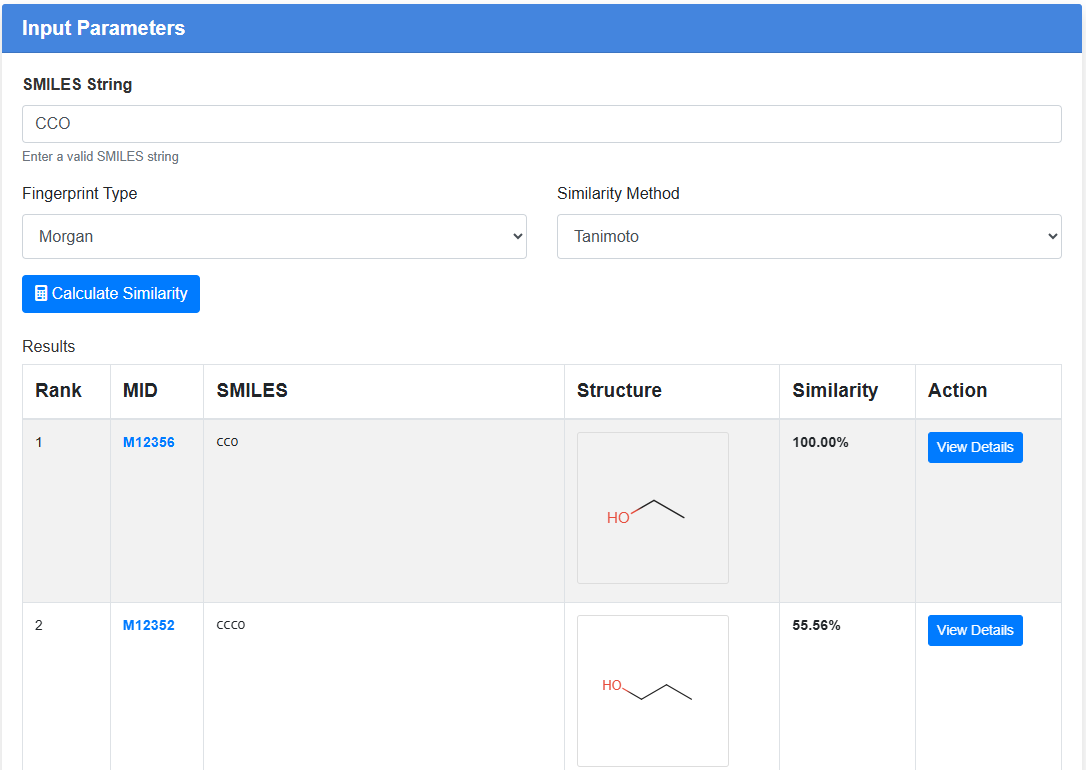
化合物相似性分析:
输入SMILES字符串,选择指纹类型(Morgan、RDKit、MACCS、原子对或拓扑扭转)和相似性方法(Tanimoto、Dice、Cosine、Sokal或Russel)。该工具将计算与数据库中所有化合物的相似性分数,并显示最佳匹配及其结构。
-
肽性质分析:
使用单字母氨基酸代码(A-Z)输入肽序列。该工具将计算各种性质,包括分子量、Atchley因子、Kidera因子、疏水性、等电点和净电荷。结果以表格和雷达图的形式显示,类似于肽详情页面。

-
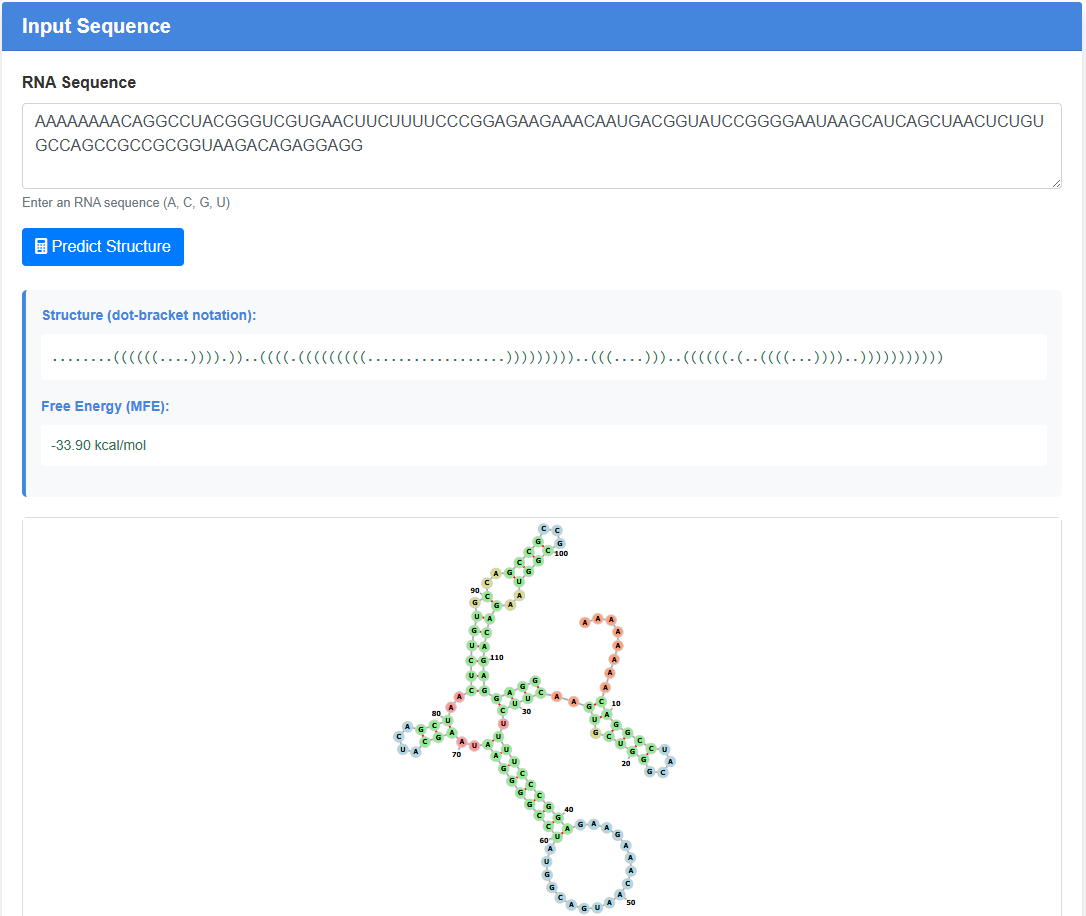
RNA二级结构预测:
输入RNA序列(A, C, G, U)。该工具使用ViennaRNA预测二级结构,并通过交互式可视化显示。结构以点括号表示法和2D结构图的形式显示。